(서비스 레지스트리)
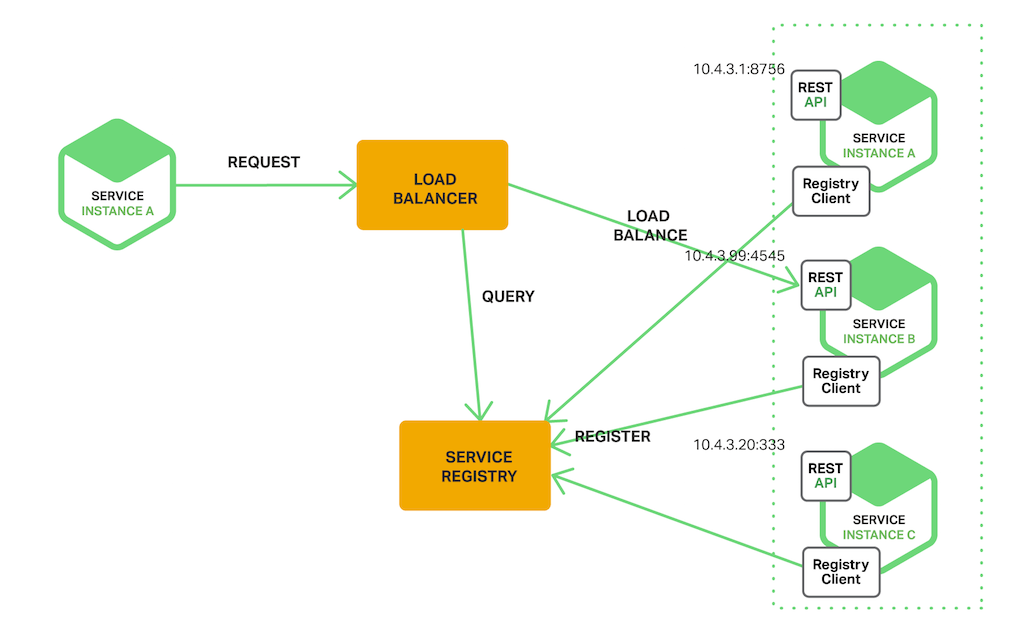
서비스 레지스트리는 서비스 검색의 핵심적인 부분이다. 서비스 레지스트리는 서비스 인스턴스의 네트워크 상 위치를 포함하고 있는 데이터베이스이다. 서비스 레지스트리는 고가용성이어야 하고, 최신 상태가 되어 있어야 한다. 클라이언트는 서비스 레지스트리를 통해서 얻은 네트워크 위치를 캐시할 수 있다. 그러나 캐시한 정보는 점차적으로 오래된 데이터가 되고, 클라이언트는 서비스 인스턴스를 검색할 수 없게 된다. 결과적으로, 서비스 레지스트리는 일관성을 유지하기 위해서 복제 프로토콜을 사용하는 서버 클러스터로 이루어진다.
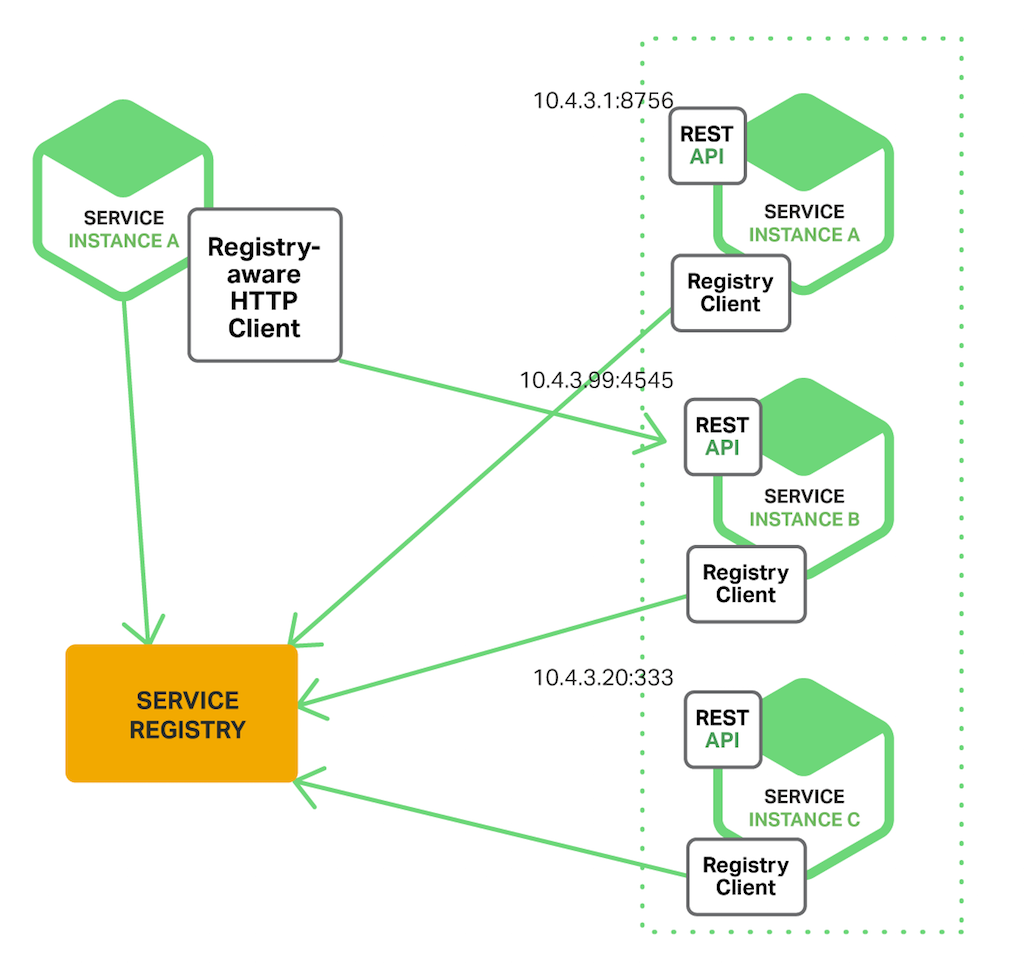
앞에서 언급했듯이, Netflix Eureka는 서비스 레지스트리의 좋은 예이다. 서비스 인스턴스를 등록하고 질의하기 위한 REST API를 제공한다. 서비스 인스턴스는 POST 요청을 사용하여 네트워크 상의 위치를 등록한다. 매 30초마다 PUT 요청을 사용하여 등록 정보를 새로 고쳐야 한다. 등록 정보는 HTTP DELETE 요청을 사용하여 삭제되거나, 등록 시간 초과에 의해 제거된다. 예상한 것처럼, 클라이언트는 HTTP GET 요청을 통해서 등록된 서비스 인스턴스를 조회할 수 있다.
Netflix는 각 Amazon EC2 가용성 존에서 하나 이상의 Eureka서버를 실행하여 고가용성을 실현한다. 각 Eureka 서버는 탄력적인 IP 주소를 갖는 EC2 인스턴스에서 실행된다. DNS TEXT 레코드는 Eureka Cluster 설정을 저장하는데 사용되고, Eureka Cluster 설정은 가용성 존에서부터 Eureka 서버의 네트워크 상 위치 목록까지의 맵이다. Eureka 서버가 시작되면, Eureka Cluster 설정을 얻기 위해서 DNS에 질의하고, 피어의 위치를 찾은 후 사용되지 않은 Elastic IP 주소를 할당한다.
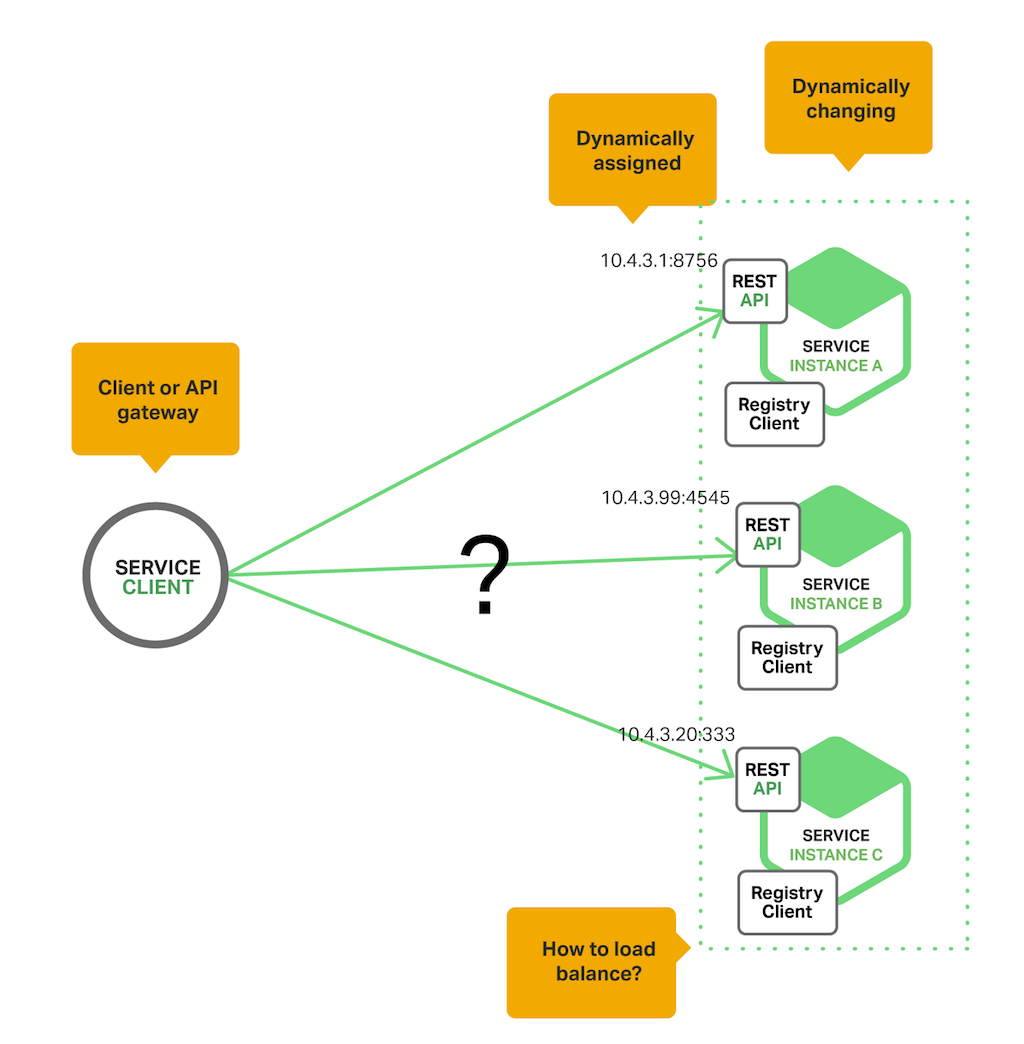
Eureka 클라이언트 - 서비스와 서비스 클라이언트 - 는 Eureka 서버의 네트워크상 위치를 찾기 위해서 DNS에 질의한다. 클라이언트는 동일한 가용성 존에 있는 Eureka 서버를 사용하는 것을 선호한다. 그러나 아무것도 사용할 수 없는 경우에는 또다른 가용성 존에 있는 Eureka 서버를 사용한다.
서비스 레지스트리의 다른 예는 다음과 같다.
- etcd : 설정의 공유 및 서비스 검색에 사용되는 고 가용적이고 분산되어 있는 일관성 있는 key-value 저장소이다. etcd를 사용하고 있는 주목할만한 2가지 프로젝트는 Kubernetes와 Cloud Foundry이다.
- consul : 서비스 검색과 설정에 사용하는 도구. 클라이언트가 서비스를 등록하고 검색할 수 있도록 API를 제공한다. consul은 서비스 가용성을 확인하기 위하여 health check를 수행할 수 있다.
- Apache Zookeeper : 분산 어플리케이션에서 폭넓게 사용되는 고 성능의 coordination 서비스. Apache Zookeeper는 원래 Hadoop의 하위 프로젝트였으나, 지금은 Top-Level 프로젝트이다.
또한, 이전에 언급했듯이, Kubernetes와 Marathon, AWS와 같은 몇몇 시스템에는 명시적인 서비스 레지스트리를 가지고 있지는 않다. 대신에 서비스 레지스트리를 인프라의 일부분으로 내장하고 있다.
지금까지 서비스 레지스트리의 개념에 대해 살펴보았다. 이제 서비스 인스턴스가 서비스 레지스트리에 어떻게 등록되는지를 살펴 보자.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/768