Implementing an API Gateway
이제, API Gateway를 사용하는 것에 대한 동기부여와 trade-off(서로 대립되는 요소 사이의 균형점)에 대해서 살펴봤는데, 이제 고려해야할 다양한 디자인 이슈에 대해서 살펴보자.
Performance and Scalability
(성능과 확장성)
단지 몇개의 회사만 Netflix의 규모로 운영되고 있고, 하루에 수십억건의 요청을 처리할 필요가 있다. 그러나, 일반적으로 API Gateway의 성능과 확장성은 대부분의 어플리케이션에서 매우 중요하다. 그러므로 플랫폼에서 Asynchronous, Non-blocking I/O를 지원하는 API Gateway 만드는 것이 필요하다. 확장 가능한 API Gateway를 구현하기 위해 사용하는 기술들은 다양하다. JVM상에서 Netty, Vertx, Spring Reactor, JBoss Undertow와 같은 NIO(Non-Blocking I/O) 기반 framework를 사용할 수도 있다. 일반적으로 Chrome의 Javascript engine인 Node.js도 non-JVM 기반의 한가지 선택이 될 수 있다. 또다른 선택은 NGINX PLUS를 사용하는 것이다. NGINX PLUS는 성숙하고 확장 가능하며 고성능의 웹 서버와 쉽게 배포할 수 있고, 설정 가능하고, 프로그램될 수 있는 reverse proxy를 제공한다. NGINX PLUS는 authentication(인증), access control(접근제어), load balancing requests(요청 부하 분산), caching responses(응답 캐싱), 어플리케이션을 인식하는 health check와 모니터링을 관리할 수 있다.
Using a Reactive Programming Model
(반응 프로그래밍 모델 사용:이벤트를 비동기 데이터 흐름으로 보는 프로그래밍 방법)
API Gateway는 어떤 요청들에 대해서는 간단히 적합한 backend service로 전달한다. 다른 요청들에 대해서는 여러 개의 backend service를 호출하고, 그 결과를 취합한다. 상품 상세 정보 요청과 같은 어떤 요청들은 서로 독립적인 backend service에 요청하기도 한다. 응답 시간을 최소화하기 위하여, API Gateway는 동시에 독립적으로 요청을 처리해야 한다. 그러나, 때때로 요청 사이에는 의존 관계가 있다. API Gateway는 요청을 backend service로 전달하기 전에, 처음에 authentication service(인증 서비스)를 호출하여 요청에 대해 인증할 필요가 있다. 이와 유사하게, 고객의 wish list에서 상품에 대한 정보를 가져오려고 할 때, API Gateway는 먼저 정보를 담고 있는 고객의 프로파일을 조회하고, 각 상품에 대한 정보를 조회해야만 한다. API composition(구성)의 또다른 흥미로운 예제는 Netflix Video Grid이다.
전통적인 asynchronous callback approach로 API composition code를 작성하면, 여러분은 빠르게 callback hell에 빠지게 된다. Code는 꼬이고, 이해하기 어렵고, 오류가 발생하기 쉽다. 더 좋은 방법은 reactive approach를 사용하여 서술 형태로 API Gateway Code를 작성하는 것이다. Scala의 Future, Java 8의 CompletableFuture, Javascript의 Promise가 reactive abstraction의 예이다. 물론, .ㅜNET Platform을 위해서 Microsoft에서 개발한 Reactive Extension(Rx or ReactiveX라고도 불린다.)도 있다. Netflix는 그들의 API Gateway에서 특별하게 사용하기 위해 JVM에 대한 RxJava를 만들었다. 물론 브라우저와 Node.js에서 모두 동작하는 Javascript를 위한 RxJS도 있다. Reactive approach를 사용하면 API Gateway code를 굉장히 효율적으로 작성할 수 있을 것이다.
Service Invocation
(서비스 호출)
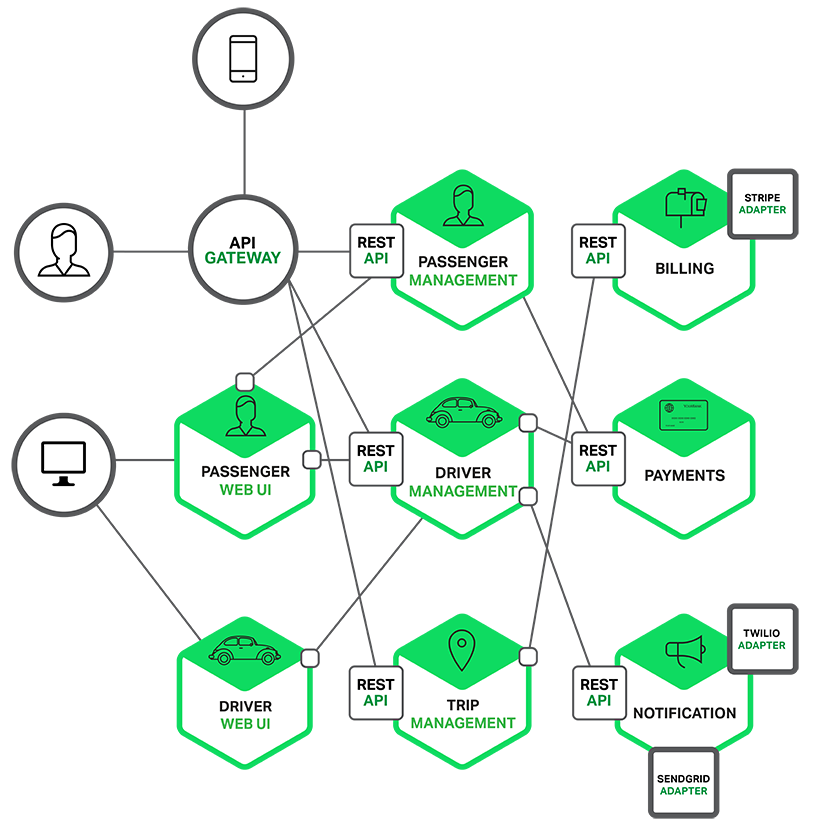
Microservice기반 어플리케이션은 분산 시스템이기 때문에 inter-process communication mechanism(프로세스간 통신 매커니즘)을 사용해야만 한다. Inter-process communication에는 2가지 형태가 있다. 한가지는 비동기 메시지 기반 메커니즘을 사용하는 것이다. JMS나 AMQP와 같은 message broker를 사용하여 구현한다. 나머지는 ZEROMQ처럼, broker 없이 서비스들이 직접 통신하는 메커니즘이다. 또다른 inter-process communication 형태는 HTTP나 Thrift와 같은 비동기 메커니즘이다. 시스템은 동기, 비동기 모두 사용할 수도 있고, 각각의 형태의 여러 구현체들을 사용할 수도 있다. 따라서, API Gateway는 다양한 통신 매커니즘을 지원해야 한다.
Service Discovery
(서비스 발견)
API Gateway는 통신할 각 microservce들의 위치(IP 주소와 port)를 알고 있어야 한다. 고전적인 어플리케이션에서는 위치를 고정시켰으나, cloud기반 microservice 어플리케이션인 현대에는 심각한 문제이다. Message broker와 같은 기초적인 서비스는 OS 환경 변수를 통해 특정지을 수 있는 고정 주소를 가지고 있을 것이다. 그러나, application service의 위치를 결정하는 것은 그렇게 쉽지 않다. Application service는 동적으로 지정된 주소를 가지고 있다. 또한, service의 여러 instance들은 autoscaling과 upgrade때문에 동적으로 변한다. 따라서, 시스템에서 다른 서비스의 클라이언트와 같은 API Gateway는 시스템의 서비스를 발견하는 메커니즘을 사용해야 한다. 그것이 Server-side Discovery이건 Client-side Discovery이건 간에. 나중에 service discovery에 대해서는 더 자세히 다룰 것이다. 우선은 시스템이 Client-Side Discovery를 사용한다면 API Gateway가 모든 microservice instance들과 그 위치에 대한 데이터베이스인 Service Registry에 질의할 수 있어야 하는 것에 대해서 기록할만한 가치가 있다.
Handling Partial Failures
(부분적인 실패 처리)
API Gateway를 구현할 때 고민해야할 또다른 이슈는 부분적인 실패에 대한 문제이다. 이 이슈는 하나의 서비스가 또다른 서비스를 호출할 때, 느리게 응답하거나 사용불가능한 경우, 언제든지 모든 분산 시스템에서 발생한다. API Gateway는 downstream service(API Gateway에서 요청을 전송한 서비스)에 대해서 무한대로 기다리며 차단하지 않아야 한다. 그러나, 특정 시나리오에서 발생하는 실패와 서비스가 실패하는 경우는 어떻게 다루어야 하는가? 예를 들면 상품 상세 정보 시나리오에서 추천 서비스가 응답하지 않는다면, API Gateway는 아직 사용자가 사용중이기 때문에 client에 나머지 상품 상세 정보를 보내 주어야 한다. 추천 내용은 비어 있거나, 예를 들어 고정된 top 10 리스트 같은 내용으로 교체될 것이다. 그러나 만약 상품 정보 서비스가 응답을 하지 못하는 상황이라면 API Gateway는 client에 에러를 리턴해야 한다.
API Gateway는 캐시를 사용할 수 있도록 되어 있을 경우, 캐시된 데이터를 리턴할 수도 있다. 예를 들어 상품 가격이 수시로 변경될 경우 API Gateway는 상품 가격 서비스를 이용할 수 없을 경우, 캐시된 상품 가격 데이터를 리턴할 수 있다. 데이터는 API Gateway 자체에 캐시되거나 Redis, Memcached와 같은 외부 캐시에 저장될 수 있다. 기본 데이터나 캐시 데이터를 리턴하여 API Gateway는 시스템에서 발생한 실패가 사용자 경험에 영향을 미치지 않도록 한다.
Netflix Hystrix는 remote service를 호출하는 code를 작성하는데 믿을 수 없을 정도로 유용한 라이브러리이다. Hystrix는 특정 한계점을 넘어서는 호출을 중지시킨다. Circuit breaker pattern으로 구현되었는데, 응답하지 않는 서비스에 대해서 client가 불필요하게 기다리는 것을 멈추게 한다. 만약 서비스의 error rate가 특정 한계점을 넘어간다면, Hystrix는 circuit breaker를 작동시키고, 모든 요청들은 즉시 특정 기간동안 실패할 것이다. Hystrix는 캐시를 읽거나 기본값을 리턴하는 것과 같은 요청이 실패할 때, callback action을 정의할 수 있다. 만약 JVM을 사용한다면 Hystrix를 사용하는 것을 분명히 고려해 보라. 만약 non-JVM 환경에서 구동시키고 있다면, 동등한 라이브러리를 사용해야 한다.


댓글을 달아 주세요
댓글 RSS 주소 : http://www.yongbi.net/rss/comment/756